V = C / E
(Post-money) Valuation = Capital Invested / Equity (as a decimal fraction in the range [0,1])
It’s one of the most important yet difficult points of negotiation in any capital raise. Important because it has long-lasting implications on financial returns, difficult because there is so little data to objectively determine a fair valuation when companies are in the early stages. Every investor, founder, consultant, ecosystem cheerleader, and their academically titled cat has a different view on how to approach valuation - here are some of the most common narratives:
How much money does the company need? I’ll buy 20% of the company for that, thanks.
How much money does the company need? I’m not giving up more than 0.24% equity so that determines the lowest valuation I’m willing to entertain.
What have other start-ups been valued at recently? Let me copy your homework, I’ll change it up a bit so it’s not obvious.
What was the company’s last valuation? Surely it can’t have tripled in the last 18 months, let’s call it 2.5x and move on.
Let’s apply a market multiple to your annual revenue. Don’t have any revenue yet? Well guess what it might be in 5 years time and we’ll discount it backwards, despite every single number in this process being a made-up assumption.
Here’s a spreadsheet that my third cousin’s physiotherapist gave me that has a lot of numbers in it, and it tells us the valuation is this. Just trust the spreadsheet.
What stage is the company? Someone in the US said to use these rules of thumb so now you’re worth a clean round $1 million.
How much would it cost to rebuild everything that the company has so far? Oh, that number’s really small, what if we also add in *waves hands* future potential?
What valuation does the company want to raise at? Whatever the number is, they have rocks in their head and we’ll slash it in half.
I was involved in a similar company ten years ago with a different product selling to a different market with a different team, so this company should be worth about the same.
Let’s propose this valuation. Oh, the company is using AI? We can triple it then!
Let’s use a convertible note so we don’t have to talk about valuation (yet).
If many of these narratives sound a bit… dumb, it’s because they are. Yet people will spend a lot of time debating valuation numbers, with little evidence and mostly vibes.
Ideally, the valuation should be the result of any other free market pricing mechanism - a willing buyer (investor) is happy to pay the price agreed with a willing seller (founders/company). But there are no pure free markets, and investing in start-ups is no different. There are supply constraints (limited investment capital), imperfect information exchanges (everything is confidential), and huge power differentials between the investors and the founders/companies (one party has all the money, the other party needs some of it, please). And despite the inherent unfairness in the market, you do still have to come up with a number that everyone can live with.
So now onto the controversial bit - New Zealand start-ups valuations are too low. Investors don’t want to hear it, because they think they benefit from low valuations (and are also mostly responsible for setting the valuations). Founders don’t want to hear it, because it’s depressing to know that keeping your company at home puts you personally at a financial disadvantage, and who wants to deal with the cost of living in San Francisco anyway? And my cat doesn’t want to hear it, because if it’s true, there are much broader economic implications that could be holding the New Zealand start-up ecosystem back from success (and therefore, after several jumps in logic, lead to less regular wet food and fewer treats). But firstly, let’s look at the evidence.
Is the claim true?
Exhibit A
Everyone has their stories (and I share a few in the below sections), but quantitative data paints the clearest picture. Pitchbook is regarded as the imperfect but most comprehensive data aggregator for the private investment industry. They scour the internet for press releases and they ask investors to update the data on their deals - while they might miss some capital raises or get some data points wrong, it’s mostly better than their competitors. Licences to access the data are pretty expensive, but anyone who wants to do valuation properly needs to have access to data about market trends and comparable start-up companies.
A few years ago, I participated in an exercise to compare New Zealand start-up valuations to those found in a handful of other geographies. Shout out to Liam Rollo (now in Australia with Breakthrough Victoria) for doing the heavy lifting of analysing the Pitchbook data. We looked at Deep Tech and SaaS companies with Seed, Series A, and Series B capital raises for the three year period between 5 July 2019 and 5 July 2022. All figures in the below tables are standardised to USD.
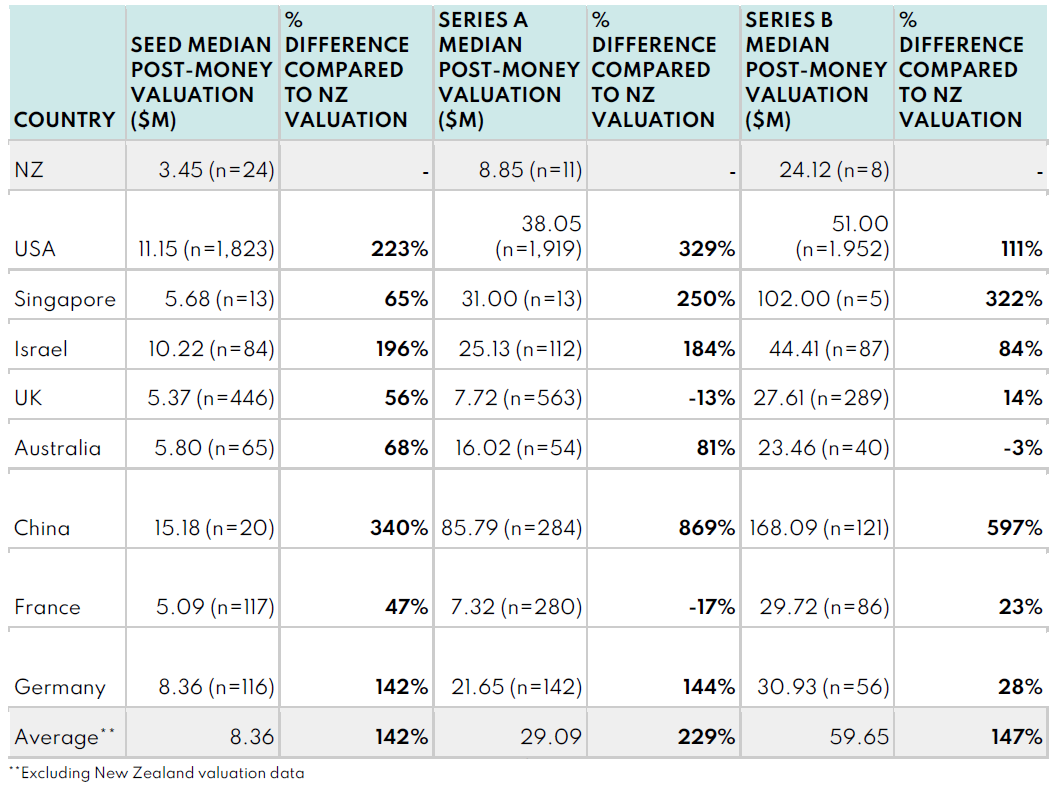
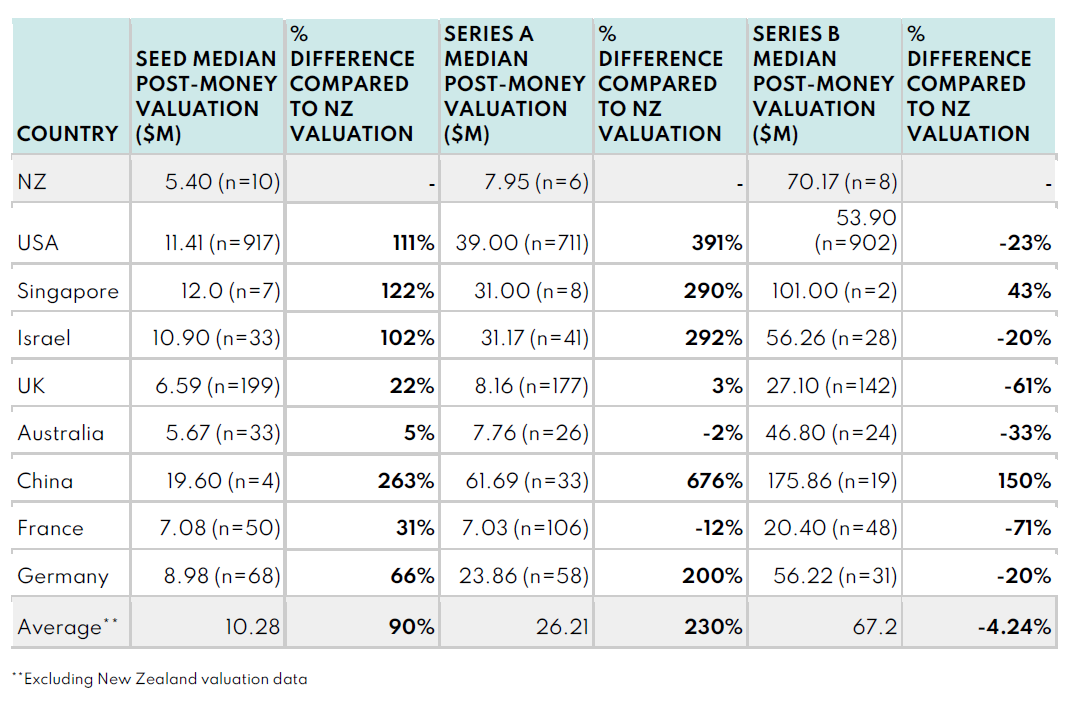
Deep Tech Valuations
Before anyone gets too excited, yes the New Zealand sample sizes are small, and there is a feeling that there should be more data points in there (particularly on the SaaS side), but the medians seem consistent with other data sources like the Startup Investment New Zealand report. These are medians, as to minimise the impact of outliers, so that one company you’re thinking of that bucks the trend isn’t really relevant to this discussion. The stage definitions are based on how the capital raise was classified in Pitchbook, so there may be differences in expectations between jurisdictions. We can and should challenge the robustness of any claims made on the basis of this limited data, but it’s also the best data we have, and the size of the effects are just so large that we need to pay attention.
The data shows that NZ start-up valuations are lower than in jurisdictions we like to compare ourselves to (like Singapore, Israel, UK, Australia), and a lot lower than in the USA, especially for really early-stage companies (Seed). To describe the percentages in the opposite direction, NZ Seed-stage deep tech valuations are about 70% lower than in the USA, and NZ Seed-stage SaaS valuations are about 53% lower than in the USA.
We also looked deeper into the data - both more historically (back to 2010) and more longitudinally (for companies up to Series D). There are a lot of data tables that I won’t include here, but we found the valuation gap to be persistent (60-70% lower Seed valuations than USA from 2010-2022) and reducing as companies become more mature (Series D valuations were much more similar to international counterparts). On the latter point, we identified that NZ company valuations “catch-up” to other jurisdictions as the companies grow, because as the rounds get larger the higher the likelihood of NZ companies raising capital from international investors, with international investor valuation expectations.
Exhibit B
Some of the local investors know this claim to be true, because they say so in their pitch decks when raising capital for their Funds. Out of the slides that I’ve seen over the years, one pitch deck from 2021 says New Zealand has “many undervalued startups: 30% below the Bay Area”; another from 2022 says NZ “Valuations are ~50% below US startups”. Peter Beck is quoted in TechCrunch saying “New Zealand’s valuations on average are about 50% lower than most companies coming out of Silicon Valley”. As the data in Exhibit A shows, these estimates might be generous to NZ.
Why is this a relevant point to put in a pitch deck for a fund? International investors are being told “hey, invest in New Zealand start-ups because you can score yourself a deal!” Buy low(er), sell high! The implication is that companies of comparable quality and likelihood of success are significantly cheaper in New Zealand than in California. In economics terms, if there is such a significant arbitrage opportunity for investors, where are the market corrections? Or is something keeping the market inefficient? More on this later.
Exhibit C
Most early-stage start-ups (particularly pre-seed/seed) are funded by local New Zealand investors. They’re the investors that understand the ecosystem, know how to navigate the regulatory landscape, and can most easily develop connections with the founders. But every now and then, an international investor sees opportunity here, and blows all the local investors out of the water.
Just last year, a promising start-up attracted the interest of an Asian VC fund at Seed stage. Local investors submitted term sheets with a (pre-money) valuation around NZD$5M, and even then it was like pulling teeth, with most local investors commenting that it was way too high. The international investor offered a (pre-money) valuation of NZD$12M. No chocolate fish for guessing who the start-up went with! Why was there such a big gap? This was the international investor’s first term sheet in New Zealand, and they didn’t come to play the New Zealand game - they were already competing in a global game that most local investors have no idea how to play.
Exhibit D
The recent Callaghan Innovation Technology Incubator Request for Proposals has an answer to a question about equity expectations that says “Our policy settings state that Technology Incubators are expected to use their investment to purchase up to 20-50% of equity in the start-up. Requiring 20-50% equity is intended to ensure that only sufficiently early stage and complex/deep tech start-ups are invested in.” That’s a government agency telling the market that they expect valuations to allow for 20-50% equity to be taken in exchange for a $250k investment (plus the $750k Repayable Grant that should be treated as debt, not equity). In a worst case scenario, that’s effectively a (pre-money) valuation of $250k for a pre-seed company, and in the best case a (pre-money) valuation of $1M. This is worse than just signalling, because this is an active intervention that is suppressing valuations below what the market might otherwise provide. [To be fair to Callaghan, they also say that a lower 10-20% equity holding can be approved where there is a strategic investment syndicate - but you can cross-reference the recipients of Repayable Grants with ownership data on the Companies Office to see how frequently that has happened. And to be fair to Callaghan, if the intervention is supporting companies that otherwise wouldn’t have raised capital, then arguably it serves its purpose.]
What are the consequences?
So I think the evidence shows NZ start-up valuations are low, but also that they’re probably a lot lower than most people might have expected. And moving away from evidence towards reckons, I believe that a NZ Seed stage start-up should not be 30%, 50%, or even 70% less valuable than a comparable company in the US just because it’s working out of New Zealand. Sure, US companies draw from a larger pool of founders, there is a stronger network effect, and they are operating in larger markets, but 70% seems too much of a difference. Some might claim that this is the impact of exchange rates, but at most that would have a 33% impact (and given that it is a more predictable element of valuation, more priced in).
If valuations are artificially lower than where they should be, then there are two key consequences for Kiwi start-ups. The first is that, assuming the company needs a fixed $x to be able to get to the next capital raise, then a low valuation will lead to investors taking a larger proportion of the company. The people working in the company (including founders and equity-remunerated staff) will therefore earn less of the financial reward if they are successful. We might say, who cares, they’ll still be rich - but the main problem is that when the companies seek subsequent rounds of capital, bigger (and often international) investors claim that the “cap table is screwed” because the “founders are insufficiently incentivised to outperform”. And then they say the dreaded word that no one really wants to talk about: recapitalisation. A bunch of pain and difficult conversations, because the earlier valuations were too low. Or worse, no capital raise (and therefore company failure) because no one wants to do the work of a recap, or the investors can’t all agree before the company runs out of time.
The second consequence is that, assuming the investors want a set percentage of equity (some investors have a minimum requirement to make it worthwhile for them, some investors have an upper limit that they are willing to hold for risk diversification reasons), then a low valuation will lead to the company being undercapitalised. That is, the company won’t be able to make enough progress, or be able to spend on things that would make the company successful, and then fail to impress investors at the next capital raise. The Startup Genome report for NZ states (slide 72) that “The Median Series A round for NZ startups is quite small compared to peer ecosystems… and make[s] them look less attractive to future investors.” Kiwis are proud of their Number 8 wire mentality and being able to make a dollar stretch further than overseas competitors, but efficiency doesn’t necessarily lead to winning, and it can also be another source of failure risk. A bunch of wasted talent, time, effort, and sweat, because the earlier valuations were too low.
These are both generalisations, but they also happen far too often in the New Zealand market. And unlike other reasons that a company might fail (lack of product-market fit, competition, regulatory/legal challenges) which are mostly external and beyond the direct control of the company, valuation is entirely within the control of the company and its investors, who should be aligned in wanting the company to succeed.
Even where the company does manage to make progress, start-ups where the founders have less equity are more likely to exit early, for lower amounts of money. This limits the potential returns for both founders and investors, which reduces the amount they have to invest in further ventures, which delivers poor performance and track records for the ecosystem, and the flywheel of growth never really kicks off. This is where the problem can be hard for individuals to rationalise but is actually really consequential - it's not a problem that just affects individual companies, but the performance of the ecosystem as a whole, and therefore its contribution to the national economy.
I note here that there are some claims that valuation is negatively correlated to failure rate (i.e. companies with lower valuations are more likely to fail). I don’t think this correlation is relevant because companies also get higher valuations as they make progress and succeed and get to subsequent stages of capital raising. Success breeds success, so to say that a metric that is a proxy for success is negatively correlated to failure isn’t that interesting. If the described correlation was within a funding stage, then maybe there is a point, but I haven’t seen any data demonstrating that yet.
Are the (systemically) lower valuations hurting our ecosystem as a whole?
To be clear, valuations that are too high present their own set of challenges, so jumping to sky-high valuations isn’t going to solve the problem for New Zealand either. Why we shouldn’t immediately copy Bay Area valuations requires another standalone article that talks more about culture and hubris. And an important point for companies seeking an acquisition exit pathway - valuations that are too high might eventually price your company out of an acquisition.
It’s hard to concretely make a claim about the ecosystem though. In theory, low valuations disincentivise founders from taking on the risk of going on a start-up journey because they will probably get less reward out of it, but I don’t believe many founders in NZ think in that way. No one wants to leave money on the table of course, but most founders are doing start-ups because they are passionate about their idea and want to make their mark on the world [and sometimes they want to be their own boss and exercise a high locus of control but find out quickly that even CEOs have bosses - that dynamic is worth another article].
Something that we are missing in the NZ ecosystem is a rigorous, broad study of start-up company failures (also morbidly called post-mortems) to produce evidence for any common themes (and therefore inform potential interventions to mitigate risk). Probably because most people don’t like to talk about failure, so the stories get swept under the rug. Do we have more start-ups failing in NZ than other comparable jurisdictions? We have no idea.
But I think that low valuations are symptomatic of investor behaviour where the emphasis appears to be on “scoring a deal” in the short-term, and forgetting (or wilfully ignoring) the long-term impacts.
Take the issue of high founder dilution leading to difficult capital raises later down the line (and likely recapitalisation). All professional investors know that future investors will need to see the founders holding sufficient equity, yet we still see Pre-seed and Seed rounds where the investors are happy to take up to 50% equity. I’ve seen multiple companies where the founders have told their existing investors that potential future investors are signalling that there are cap table issues - and the Board/investors do nothing because they hope that it will all work out for them. While company failure can usually be attributed to multiple reasons, there have been a bunch in the last year alone that can likely be attributed to cap table structures making it that much easier for potential investors to say no in a tough capital market, and then the company running out of money.
A significant factor in the New Zealand ecosystem is that there is relatively low competition amongst investors, which leads to cartel-like behaviour (which, to be clear so that no lawyers get mad at me, is not the same as cartel behaviour). Local investors all talk to each other about potential investments, and while there isn’t price-fixing via closed-door agreements to offer low valuations to start-ups (that I know of), there’s plenty of social signalling and pressure that leads to herd behaviour. Most people don’t want to look dumb or be judged by their peers for offering high valuations - and even those who don’t care have Investment Committees or other governance entities that try to ensure that the investors are getting a good deal. And consistently high(er) valuations can make it hard to syndicate/work with other investors who still have low valuation expectations, which can leave you quickly isolated in an ecosystem that needs a lot of co-operation to succeed.
Unfortunately, investors thinking they are getting themselves a short-term win can often become long-term losers. Owning 50% of a company that has failed is still a $0 outcome. And an ecosystem that is full of short-term wins has to be pretty nervous about its long-term prospects. It’s hard enough to generate a win, so we shouldn’t let valuation add any more risk than absolutely necessary.
What do we do about it?
There are two parties that could do something here. NZ investors could realise that (artificially) low valuations actually hurt them in the long-run, and start benchmarking their expectations to international numbers. We keep telling our founders and companies that they need to play in the international markets and set their sights overseas as soon as possible because New Zealand is too small - why don’t investors take some of their own advice? Investors are in a position of power in most investment discussions and negotiations, and I believe there is a duty of care owed to the founders - remember that most founders have N=1 experience (i.e. their own company), whereas investors are acting with N>1000 information. If the investors don’t know how to set a valuation well, then maybe they should consider using convertible/SAFE notes to reduce the likelihood of making a mistake (even if it might come at the cost of lower short-term returns).
While some people reading this article might sagely nod their heads, most investors will be frothing at the mouth and deleting my phone number from their contacts, so I don’t think we can realistically hope for a collective Eureka moment. When markets are inefficient or imperfect, we have to call upon governments to introduce interventions and regulations. Telling founders that investors should take up to 50% of their company for a pre-seed round is wildly in the wrong direction - it’d be like the government saying that all houses should be worth at least $2 million. Removing that poor signalling would be a good start.
Collecting and releasing better (anonymised) data would help reduce information asymmetry and allow all investors and founders to make fairer decisions about valuation/pricing. New Zealand Growth Capital Partners (NZGCP) already collects a lot of this data, but hasn’t been resourced sufficiently to produce benchmarks (but maybe the new Dealroom database will help). Promoting competition by supporting the establishment of more professional investment firms, rather than supporting the same existing ones, could also force incumbents to have tougher conversations about innovating on their investment models. Other policies to increase the attractiveness of investing into start-ups generally (another article in itself) would also hopefully increase capital supply and therefore likely have an upwards effect on valuations - but we’d need a lot of capital (like perhaps a 1%-of-all-Kiwisaver-funds amount of capital) to close the gap on other jurisdictions.
These are pretty mild as suggestions go. It’s not like I’m saying the government should establish price controls and say all start-up companies have to be valued at a certain minimum level, or to do ~something~ to the tax system. I once pitched the idea of a government-backed founder insurance scheme and a relatively prominent investor called me a Communist (which he probably thought was more insulting than I took it), so big ideas don’t scare me. But I get that it can be costly to make noise and kick up a fuss in an ecosystem that is small and encourages conformity, and the engineer in me asks for realistic and achievable answers.
If you have read this article and also believe that start-up valuations are probably too low in New Zealand, then keep talking about it to as many people as you can. Remember, the market is actually made up of people. Talking about these issues encourages people to actually think about what they’re doing rather than defaulting to the norm. Eventually, the norms might just shift. Maybe my instagram should be exclusively focused on start-up company valuations. Might be a bit niche.
Maybe I don’t have the answers on what to do yet, but hopefully what I’ve written here is some food for thought. My point is simply this: that higher valuations (closer to international levels) for New Zealand start-up companies could increase the likelihood of success and mitigate failure risk, giving us more winners to cheer on. Isn’t that something everyone wants?
Thanks to my awesome friends and colleagues Will McKay, Kiri Lenagh-Glue, Olivia Ogilvie, and Liam Rollo for reviewing this article and giving valuable feedback. Opinions, errors, and mistakes are my own.
If you’d like to learn more about this topic, here are a couple of resources that I read (mostly in the US context, mostly in the SaaS context) while working on this article: